


データ解析でコロナウィルス対策の評価ができる?因果推論とは何か
目次
はじめに
世界規模のコロナ禍に対して、世界中で様々な対策が行われています。国や地域によっては人の移動を完全に制限するロックダウンを実施するなど、人々の生活に大きな影響を与える施策も実行されています。
これらの施策が定性的に見て一定の効果がありそうであることは直観的にわかりますが、今後より効果的な施策を実行するためにもこれまでに行われた施策の効果を検証し定量的に評価する必要があります。検証方法は色々考えられますが、施策により感染者数の推移がどのような影響を受けたのか(どのぐらい増えたかor減ったか)を調べるのが一般的でしょう。すなわち、感染者数の推移という「データ」から施策の効果を評価するわけですから、まさにデータサイエンスの出番であるといえます。
そこで今回はデータサイエンスを用いた施策効果の評価方法例として「因果推論」という手法を解説したいと思います。また簡単な分析例として、東京都の新規感染者数の推移を利用して2021年1月7日に首都圏で発令された緊急事態宣言の効果を因果推論によって検証してみたいと思います。
因果推論とは
何らかの施策による影響を評価したい場合、最も単純に考えれば、その施策を実行した場合と実行しなかった場合の比較を行えばよいということになります。例えば科学実験などではすべての条件を同一にしたうえで特定の操作を行う場合と行わない場合での結果を比較する対照実験を行うのが一般的です。この方法であれば結果に影響を与えるのはその操作だけであるため、結果の差がそのままその操作による効果であるといえます。
しかし現実世界においてはそのような実験は不可能である場合が大半です。科学実験のような理想的な環境の構築は困難ですし、そもそも同一の条件で複数の対象を用意すること自体が原理的に出来ない場合が多いからです。
そこで、完全な対照実験が出来ない場合であっても施策による効果を推定する統計的手法が考案されてきました。そのような手法を「因果推論」といいます。
因果推論は様々な手法が考案されており、効果を推定したい対象となる施策の種類や条件によって適用できる因果推論手法は異なります。そこで今回はまず因果推論の代表的な手法をいくつか紹介したいと思います。
最も基本的な因果推論:ランダム化比較試験
因果推論の手法の中でも最も単純で、かつ最も信頼性の高い手法として「ランダム化比較試験」が挙げられます。この因果推論手法では、まず施策の対象となる母集団をランダムに複数の群に分割します。そして群ごとに異なる施策を実施し、群ごとの効果の差を調べます。
十分に大きな母集団を適切な方法でランダムに分割することが出来ているならば、それぞれの群はほぼ同じ特性を持っていると考えられます。すなわち前述の対照実験とほぼ同じ状態であると考えられるため、これらの群の間での結果の差はそのまま施策による効果であるとみなすことが出来ます。
ランダム化比較試験は、例としてマーケティングの分野において「A/Bテスト」として実際に因果推論に用いられています。例えばECサイトのデザインを2通り用意し、サイトを訪れた顧客に対してはその2通りのデザインのどちらかをランダムに表示して、それぞれのデザインにおけるコンバージョン率を集計することでどちらのデザインの方がより購買意欲向上につながるのかを因果推論で推定するといったものです。
このランダム化比較試験という因果推論手法はシンプルかつ施策の効果検証の信頼性も高い優れたものではあるのですが、一方で様々な理由により適用が不可能な場合も少なくありません。例えば以下のような場合が挙げられます。
ランダムな分割が不可能な場合
例えば実際に放送されたあるテレビCMを見たことがどの程度購入につながったのかについて因果推論により検証したい場合、テレビをよく見る人の方がそのCMを見る確率は高いため、見た人と見ていない人の間には傾向の差(=その人はどの程度テレビを見るのか)があると考えられ、ランダムな分割とはいえません。
集団全体へ影響が有る施策の場合
例えば自治体の施策の効果を因果推論で推定したい場合、対象となる施策はその自治体の住民全体に影響を与えてしまうため、条件が全く同一で施策の影響だけがない群を用意することが出来ません。
倫理的な理由で群を分けられない場合
例えばある病気に対する治療の効果を因果推論により調べたい場合であっても、その病気の患者の半分にのみ治療を行いもう半分は治療をしないという実験は倫理的に実行することが出来ません。
これらのようなランダム化比較試験が適用できない場合においては、その他の因果推論手法が必要となります。そこで次章からはその他の代表的な因果推論手法について紹介します。
その他の代表的な因果推論手法について
ここでは代表的な因果推論手法である「傾向スコアマッチングを利用する方法」「差分の差分法」の2つについて簡単に紹介します。
傾向スコアマッチングを利用する方法
前章で挙げた「ランダムな分割が不可能な場合」の因果推論に適用できる手法です。
例として示した「あるテレビCMを見たことがどの程度購入につながったか」について因果推論により検証したい場合、テレビをよく見る人ほどそのCMを見る確率が高いわけですから、見た人と見ていない人は全体として傾向が異なっていると考えられます。したがって単純にCMを見た人の群と見ていない人の群に分けて購入した割合を比較しても、それがCMを見たことによる効果なのか、それとも「テレビをよく見る人はこの商品をよく買う(or買わない)傾向がある」というだけなのかは分かりません。
そこで以下のように考えます。まずそのCMを見た人の群(以降A群とする)と見ていない人の群(同B群)から1人ずつ、よく似ている人のペアを抜き出します。似ている度合いは、そのCMを見る確率に影響しそうな変数(例えば、年齢、性別、職種(昼職か夜職か)、etc.)を分かる限り全て用いて比較します。
実際は大量の変数の全てが似ているようなペアはなかなか見つからないので、ロジスティック回帰などを用いて「CM視聴確率スコア」を計算し、そのスコアが近い人同士をペアにするということをします。このようにペアを作れた人だけをA群とB群から抜きだして、それぞれの群で購入に至った割合を比較するのです。すると「よく似ている人」同士の比較となるのでランダム化比較試験に近い状態となり、CMを視聴したことによる効果のみを推定できると考えられます。
差分の差分法
前章で示した「集団全体へ影響が有る施策の場合」の因果推論に適用できる場合がある手法です。
例えばある自治体で出生率を上げるような施策を実施したとし、その効果を因果推論によって検証したいとします。しかしその施策自体は当該の自治体の住民全員に影響しているので、施策を実施しなかった群を単純には用意できません。また仮に実施前と比較して出生率が上昇したとしても、それが施策によるものなのか、それとも社会全体として上昇傾向があって施策と関係なく上昇したのかを区別することが出来ません。
そこで代わりに他の自治体の出生率の推移と比較する方法が考えられます。ここでは両自治体の出生率の絶対値そのものは異なっていたとしても、施策を行わなかった場合はその推移は同じであるという仮定(平行トレンド仮定)を元に考えます。
例えば比較対象の自治体では同期間で出生率が1%下がったのに対し、施策を実施した自治体では逆に1%上昇したならば、因果推論の結果よりその施策は出生率を差し引き2%上昇させる効果があった、と評価するのです。
もちろん平行トレンド仮定は必ずしも正しいとは限りません。全く傾向の異なる自治体同士を比較してしまったり、もしくはどちらかの自治体にだけ出生率に影響を与えるような出来事(例えば天災等)が起こっていたりすれば平行トレンド仮定は破綻してしまいます。そのため、この因果推論手法を適用する際は施策前の推移の比較や影響を与える出来事の有無の調査を行うなど本当に仮定が成り立っているのかを注意深く確認する必要があります。
回帰不連続デザイン、回帰ねじれデザインの紹介
冒頭で述べました緊急事態宣言の効果を因果推論によって推定するという目的のため、「回帰不連続デザイン」と「回帰ねじれデザイン」というよく似ている2つの手法を紹介します。これらは、特定の変数に対して明確な閾値が存在していて、その閾値の前後どちらかのみに対して施策が実施された場合の効果を推定するための因果推論手法です。
例えばECサイトにおいて昨年の購入額が2万円を超えているお客様のみに特別なサービスを行ったとし、そのサービスがどの程度今年の購入額増加に繋がったのかを因果推論によって調査したいとしましょう。この場合、「昨年の購入額が2万円」というのが閾値となります。
この時、単純にサービスを行った群と行わなかった群の購入額を比較しようと思っても、一般的に昨年の購入額が高かった人の方が今年も購入額が高い傾向にあると想像できるため、その差が本当にサービスを行ったことによるものかは分からないという問題があります。
そこで以下のように考えます。昨年の購入額が閾値である2万円に近い範囲の顧客ならば、翌年の平均購入額もそれほど変わらないだろうと考えられます。例えば昨年の購入額が20,000円だった顧客と19,500円だった顧客の間には大きな差はないはずです。そのため閾値の前後の狭い範囲の顧客だけを見た場合、各顧客にキャンペーンが適用されるかどうかはランダムに割り付けられていると近似してよいと思われます。
この考え方を利用し、閾値以下と閾値以上の範囲でそれぞれキャンペーン後の購入額の回帰分析を行います。そしてそれぞれの回帰直線について閾値における予測値を比較します。もしキャンペーンが購入額増加につながっているならば、閾値の前後で予測値のジャンプが生じているはずです。したがって閾値における予測値の差が、そのキャンペーンによって増やすことのできた購入額の差であると考えられるわけです。これが「回帰不連続デザイン」という因果推論手法の考え方です。
回帰不連続デザインでは閾値という不連続点における予測値そのものの差に注目しましたが、タスクによっては閾値前後で回帰直線の「傾き」の変化が重要である場合もあります。そこで同様に閾値前後で回帰分析を行ったうえで傾きの変化に着目したのが「回帰ねじれデザイン」という因果推論手法です。
いずれの手法も「明確な閾値が存在している」「閾値付近では性質は殆ど変化しない」という前提で分析が行われるため、適用する際にはその2点についてよく確認する必要があります。
因果推論分析の方針
それではいよいよ「2021年1月7日に首都圏で発令された緊急事態宣言の効果を東京都の新規感染者数の推移を利用して検証する」という因果推論による分析タスクについて考えてみたいと思います。
分析に入る前に注意点を述べます。今回はあくまで因果推論の例を示すための分析であり、因果推論としてはかなり粗いものであることを御容赦ください。その点については分析結果を示した後に考察として述べたいと思います。また、この分析を以って政策等に対し当社としてなんらかの意見を表明するものではありませんことを御了承ください。
では今回の因果推論分析の方針を説明します。
日別の新規感染者数の推移について、おおよそ日数に対して指数関数的に変化するということが知られています。したがって特定の基準日からの日数をx(日)、日別の新規感染者数をy(人)とすると
y=10ax+b
と書けると考えられます(a, bは定数)。
指数関数のままでは扱いにくいので両辺の常用対数を取ると
logy=ax+b
となり、日別の新規感染者数の対数は日数に対する一次関数で表されるということが分かります。
実際は様々なノイズが乗っていますが、日数を説明変数として単回帰分析を行えば、上式のa, bの値を求めることが出来るはずです。
今回のタスクは「緊急事態宣言の前後で感染者数の推移の仕方がどう変化したか」を明らかにすればよいので、緊急事態宣言の前後でそれぞれ回帰分析を行い、それぞれの傾き(上式のa)を比較すればよいと考えられます。すなわち、前述の因果推論手法のうち「回帰ねじれデザイン」の考え方を利用して効果検証を行おうと思います。
今回の閾値は緊急事態宣言が発令されたタイミングということになりますが、感染者との濃厚接触から発症するまで数日かかることを考え、緊急事態宣言発令(1月7日)の3日後である1月10日以降とそれ以前で比較を行うことにします。
また閾値から離れすぎている時期では傾向が変化してしまう可能性がある事から前後1か月程度の期間を用いるのが良いと思われます。同時に、感染者数が多めに出る曜日と少なめに出る曜日があることが知られており、その影響を均すために7の倍数の日数を用いるのが良いと思われます。そこで今回は前後28日ずつの感染者数を使用することにします。
以上より、
緊急事態宣言前:2020年12月13日~2021年1月9日(28日間)
緊急事態宣言後:2021年1月10日~2021年2月7日(28日間)
として、日別の新規感染者数の常用対数を取ってそれぞれの期間内の日数で単回帰し、それぞれの回帰直線の傾きを比較します。
因果推論分析の結果
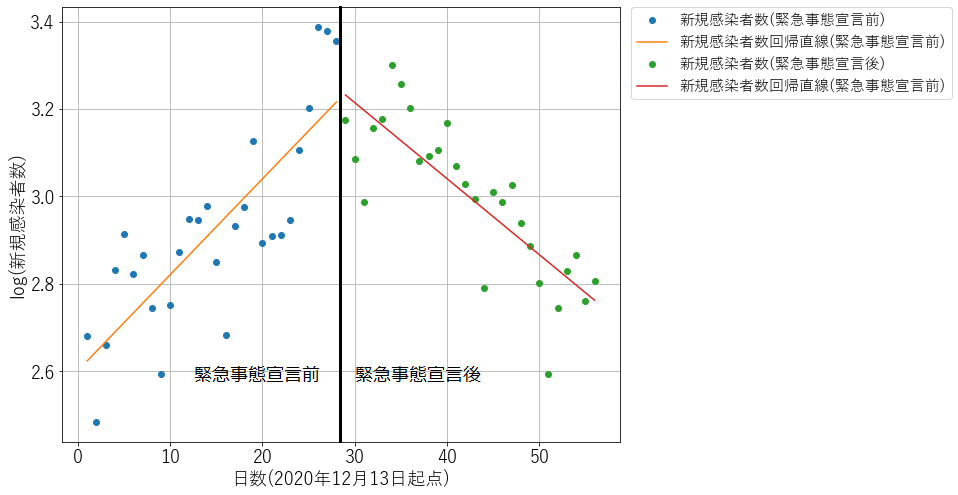 前述の通り
前述の通り
logy=ax+b
という式に基づいて回帰を行った結果を以下に示します。
| 傾きa | 決定係数R2 | |
| 緊急事態宣言前 | 0.022 | 0.650 |
| 緊急事態宣言後 | -0.017 | 0.670 |
グラフからも明らかなように、緊急事態宣言前後で感染者数の推移の傾向が異なっています。
具体的に見ていくと傾きaの値は0.022から-0.017へと変化していることが分かります。
したがって回帰ねじれデザインの考え方にしたがい、日別の新規感染者数の推移を
y=10ax+b
という式で表せると仮定した場合、因果推論によって緊急事態宣言の発令はaの値を0.039だけ低下させる効果があったと考えられます。
結果の解釈について
回帰ねじれデザインという因果推論手法に基づく分析によって緊急事態宣言はaの値を0.039だけ低下させる効果があったという結果が得られましたが、この結果はどのように解釈すればよいのでしょうか。
例えばこの0.039という値は効果として大きかったといえるのでしょうか。その検証のためには他の施策を行った場合についても同様に因果推論を行って結果を比較すればよいでしょう。とはいえ、効果の比較のためだけに試しに他の施策を実行してみるというのもまた非現実的です。コロナ禍への対応は人の生命に関わる問題であり、同時に経済活動等に与える影響も大きく、先ほども少し述べたように「倫理的な問題」が発生するからです(だからこそ回帰ねじれデザインという工夫した因果推論方法で効果を推定したともいえます)。
また施策を選択する際には単に新規感染者数の推移に対する影響だけではなく、必要なコストや経済活動へのインパクトなどを総合して考えなければなりません。すなわち因果推論によって得られた結果はあくまで一つの客観的事実でしかなく、その結果を元にどのような意思決定をするかはまた別の話になります。
今回の因果推論の例に限らず、分析結果を元にして何らかの意思決定をする際にはその分野に関する高度で幅広い知識が必要となり、データ分析技術を活用する上での難しい点の一つであるといえます。
今回の分析に関する注意点
分析を始める前にも述べましたが、今回の因果推論はとても粗い方法で行っています。実際に意味のある因果推論を行い場合は、例として以下のようなことも考慮しなければならないでしょう。
緊急事態宣言以外の影響は無かったのか
例えば緊急事態宣言以前は年末年始であり、忘年会やクリスマス、帰省といった感染拡大に影響すると考えられるイベントがありました。また検査回数や検査を行う基準なども一定とは限りません。したがって「閾値付近では性質は殆ど変化しない」という回帰ねじれデザインを適用する上での前提条件が必ずしも成り立っているとはいえず、本来はその影響も加味して分析しなければなりません。
今回の分析に限らず、各種因果推論の手法は何らかの前提条件(例えばランダム割り付けである、平行トレンドである等)を元にしている場合が多く、本当にそれらの前提条件が成立しているのかを注意深く確認することが正しい因果推論を行う際には非常に重要です。
直線で回帰するのは本当に妥当なのか
今回の例では新規感染者数は日数に対して指数関数的に推移するとし、かつaの値は緊急事態宣言前後の対象期間内でそれぞれ一定である(=直線で回帰出来る)という前提に基づいて分析を行っています。
しかし、例えば緊急事態宣言が社会に浸透するのに時間がかかっていれば効果は徐々に表れるはずですし、また気温などの天候によっても感染の拡大しやすさは変化するかもしれません。したがって、aの値も一定ではなく変化していくことを考慮する必要があるかもしれません。
閾値や日数の設定は本当に妥当なのか
今回は緊急事態宣言の発令から効果が出るまでのタイムラグを考慮して閾値を発令の3日後である1月10日に設定しましたが、これは決め打ち的に設定したものであり、本来はより慎重に定める必要があります。
また日数を前後28日ずつに設定しましたが、この期間が本当に妥当である根拠もありません。より短い方が状況の変化は小さくなると考えられますが、代わりにデータ点が減るために回帰の精度は落ちるというトレードオフの関係があり、やはり実際は様々な要素を加味して設定しなければなりません。
もちろんこれらの他にも様々な要因を考えなければならないため、因果推論を実際の問題に適用するのはかなり難しいタスクであると言わざるを得ません。逆に言えば、必要な要素をきちんと考慮に入れたうえで適切に因果推論を適用して効果を推定することこそが、データサイエンティストとしての腕の見せ所とも言えます。
まとめ
施策の効果検証を行う因果推論について代表的な手法の紹介を行い、また分析例として緊急事態宣言の効果を推定してみました。
因果推論自体はとても重要な分析手法ですが、実際に適用する際には考慮しなければならないことも多く難しい手法であるともいえます。だからこそ我々データサイエンティストの手腕が問われる部分でもあり、我々も経験をフル活用してお客様に正しい分析結果を提供できるよう日々研鑽を積んでおります。


